public static void firstReleaseThenAcquire() throws InterruptedException { Semaphore semaphore = new Semaphore(1); System.out.println("Init permits: " + semaphore.availablePermits()); semaphore.release(); System.out.println("Permits after first releasing:" + semaphore.availablePermits()); semaphore.acquire(); System.out.println("Permits after first acquiring:" + semaphore.availablePermits()); semaphore.acquire(); System.out.println("Permists after second acquiring:" + semaphore.availablePermits()); }
输出结果如下:
1 2 3 4
Init permits: 1 Permits after first releasing:2 Permits after first acquiring:1 Permists after second acquiring:0
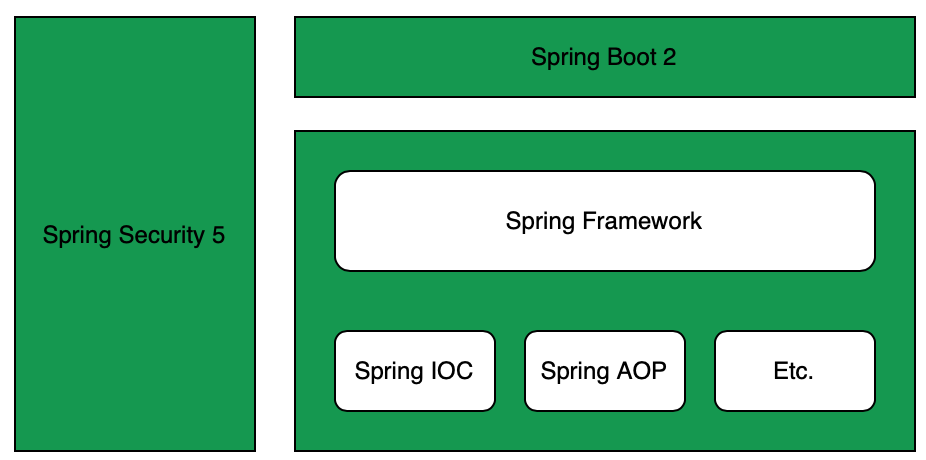
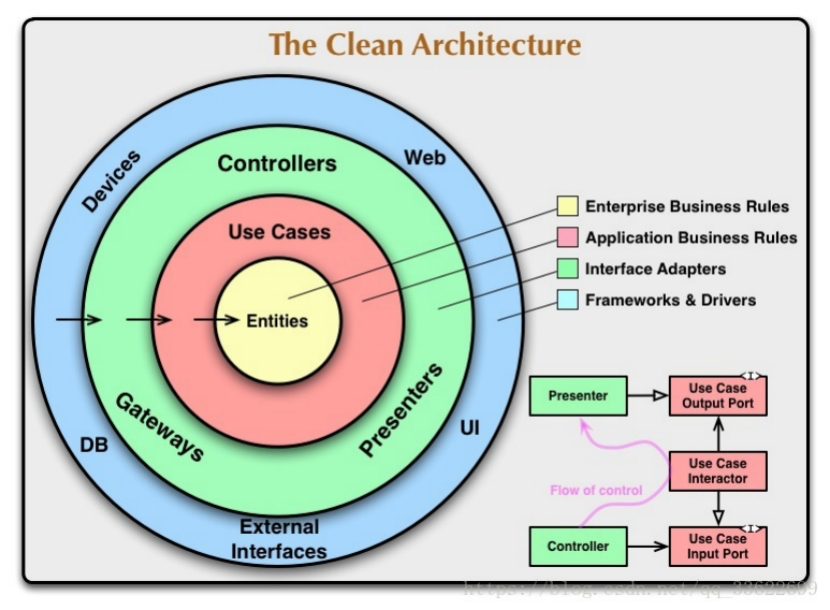
Spring Security 是一个能够为基于 Spring 的企业应用系统提供声明式的安全访问控制解决方案的安全框架。它提供了一组可以在 Spring 应用上下文中配置的 Bean,充分利用了 Spring IoC(Inversion of Control 控制反转),DI(Dependency Injection 依赖注入)和 AOP(面向切面编程)功能,为应用系统提供声明式的安全访问控制功能,减少了为企业系统安全控制编写大量重复代码的工作。
Spring Security 拥有以下特性:
对身份认证和授权的全面且可扩展的支持
防御会话固定、点击劫持,跨站请求伪造等攻击
支持 Servlet API 集成
支持与 Spring Web MVC 集成
其他的特性
Spring Security与Spring和Spring Boot的关系如下:
目前Spring Security提供以下安全技术或支持与现有技术集成:
In-Memory认证
JDBC认证
LDAP认证
Active Directory认证
Remember-Me认证
OpenID
匿名认证
JAAS(Java Authentication and Authorization) Provider
CAS认证
X.509认证
Basic And Digest认证
OAuth 2.0
SAML2
接下来先介绍Spring Security的核心组件开始。
1. 核心组件 - SecurityContextHolder, SecurityContext and Authentication
Spring Security也提供了一些UserDetailsService的实现,如InMemoryDaoImpl)和JdbcDaoImpl。但是不管如何提供UserDetailsService的实现,都可以通过SecurityContextHolder获得UserDetailsService返回的数据。
if (result != null) { if (eraseCredentialsAfterAuthentication && (result instanceof CredentialsContainer)) { (6)((CredentialsContainer) result).eraseCredentials(); }
// If the parent AuthenticationManager was attempted and successful than it will publish an AuthenticationSuccessEvent // This check prevents a duplicate AuthenticationSuccessEvent if the parent AuthenticationManager already published it if (parentResult == null) { eventPublisher.publishAuthenticationSuccess(result); } return result; }
if (lastException == null) { lastException = new ProviderNotFoundException(messages.getMessage( "ProviderManager.providerNotFound", new Object[] { toTest.getName() }, "No AuthenticationProvider found for {0}")); }
if (parentException == null) { prepareException(lastException, authentication); }
/*Proxy for a standard Servlet Filter, delegating to a Spring-managed bean that * implements the Filter interface. Supports a "targetBeanName" filter init-param * in {@code web.xml}, specifying the name of the target bean in the Spring * application context. */
/** * Returns the {@link ServletContextInitializer} that will be used to complete the * setup of this {@link WebApplicationContext}. * @return the self initializer * @see #prepareWebApplicationContext(ServletContext) */ private org.springframework.boot.web.servlet.ServletContextInitializer getSelfInitializer(){ returnthis::selfInitialize; }
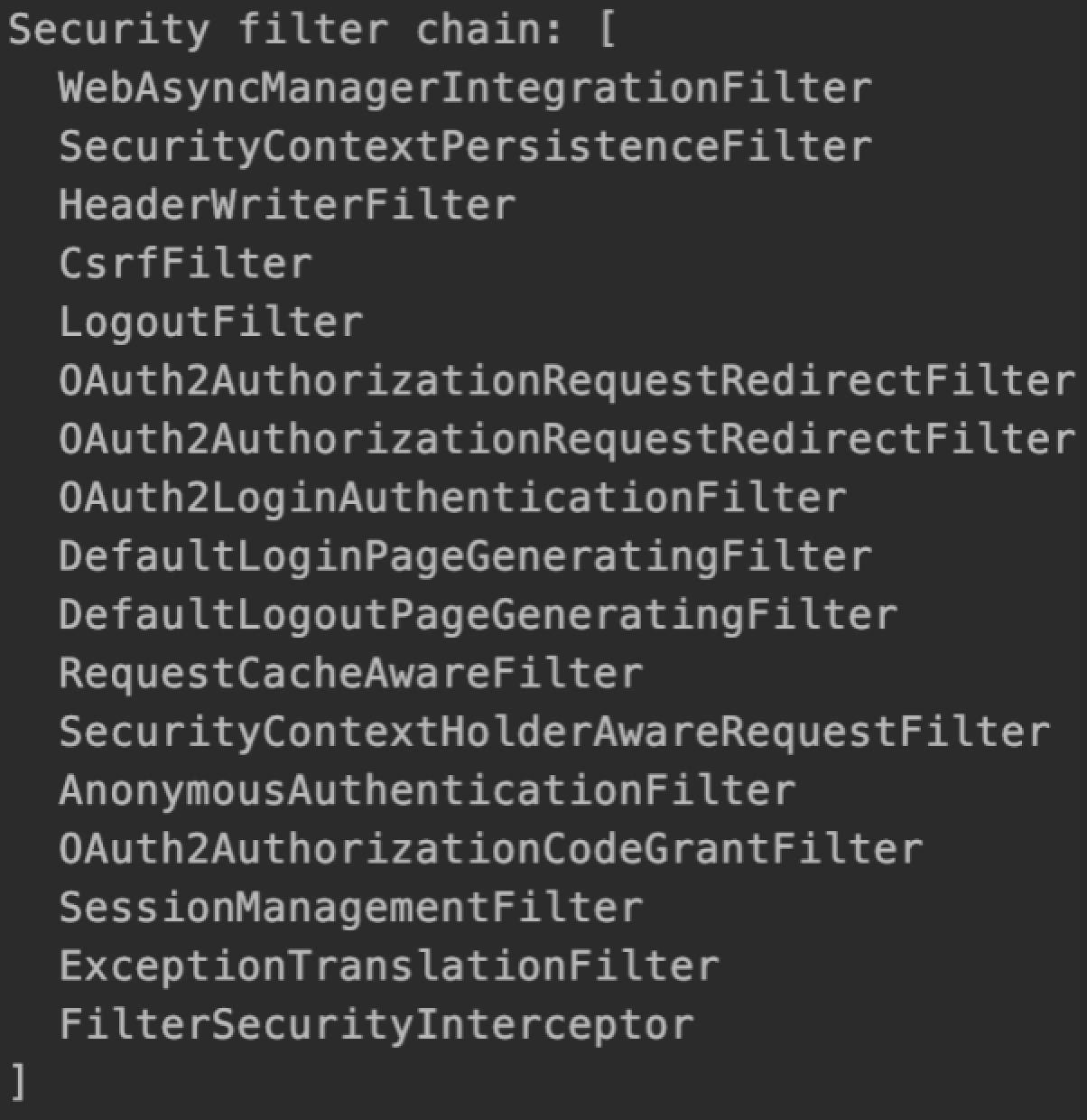
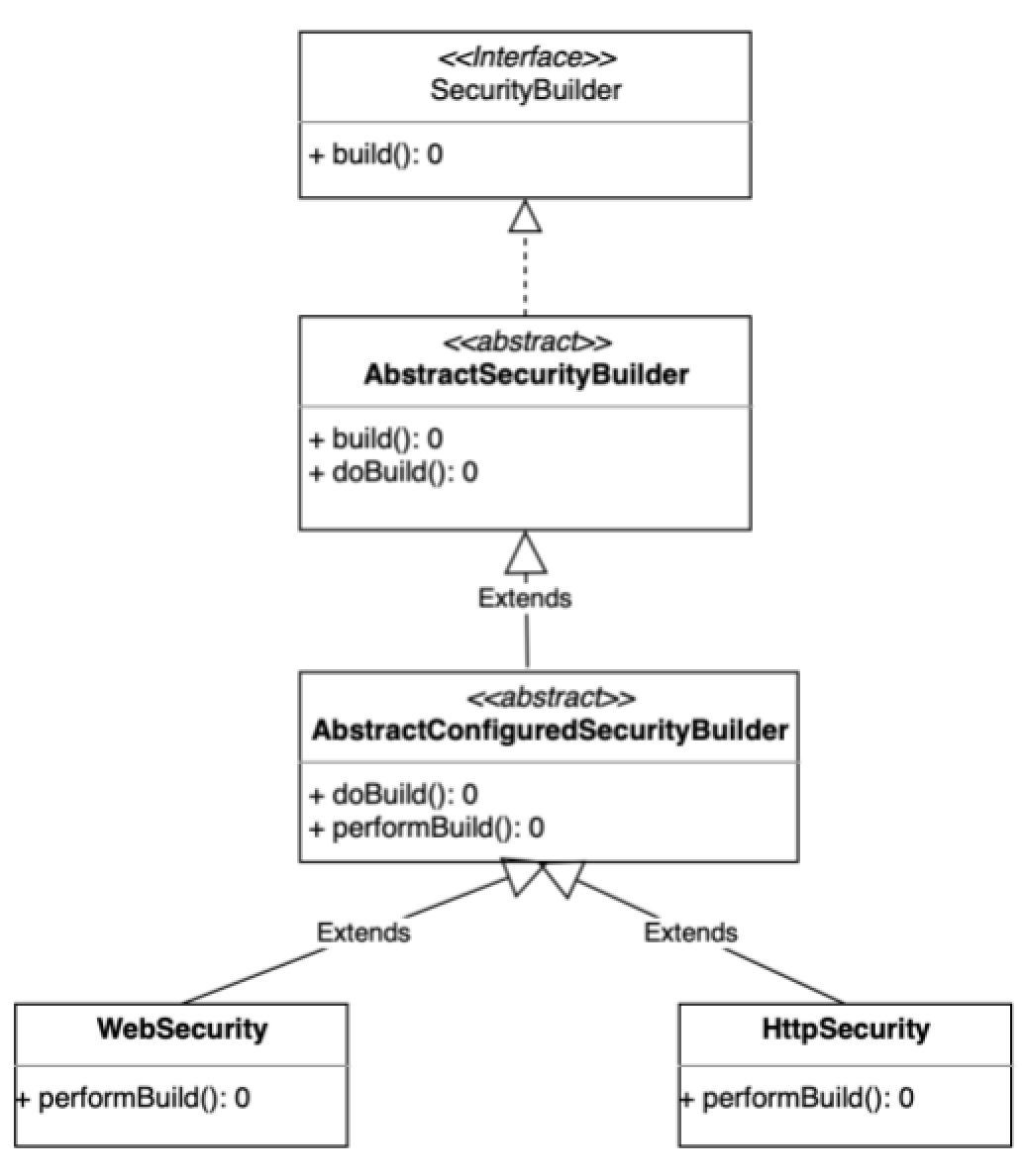
@Override protected Filter performBuild()throws Exception { Assert.state( !securityFilterChainBuilders.isEmpty(), () -> "At least one SecurityBuilder<? extends SecurityFilterChain> needs to be specified. " \+ "Typically this done by adding a @Configuration that extends WebSecurityConfigurerAdapter. " \+ "More advanced users can invoke " \+ WebSecurity.class.getSimpleName() \+ ".addSecurityFilterChainBuilder directly"); int chainSize = ignoredRequests.size() + securityFilterChainBuilders.size(); List<SecurityFilterChain> securityFilterChains = new ArrayList<>( chainSize); for (RequestMatcher ignoredRequest : ignoredRequests) { securityFilterChains.add(new DefaultSecurityFilterChain(ignoredRequest)); } (15)for (SecurityBuilder<? extends SecurityFilterChain> securityFilterChainBuilder : securityFilterChainBuilders) { securityFilterChains.add(securityFilterChainBuilder.build()); } (16)FilterChainProxy filterChainProxy = new FilterChainProxy(securityFilterChains); if (httpFirewall != null) { filterChainProxy.setFirewall(httpFirewall); } filterChainProxy.afterPropertiesSet();
Filter result = filterChainProxy; if (debugEnabled) { logger.warn("\n\n" \+ "********************************************************************\n" \+ "********** Security debugging is enabled. *************\n" \+ "********** This may include sensitive information. *************\n" \+ "********** Do not use in a production system! *************\n" \+ "********************************************************************\n\n"); result = new DebugFilter(filterChainProxy); } postBuildAction.run(); (17)return result; }